
基于参考点的非支配排序方法的进化多目标优化算法NSGA-III算法
Deb K , Jain H . An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach, Part I: Solving Problems With Box Constraints[J]. Evolutionary Computation, IEEE Transactions on, 2014, 18(4):577-601.
摘要
已经使用进化优化方法开发了多目标优化算法,并展示了它们在涉及两个和三个目标的各种实际问题上的优势,现在越来越需要开发进化多目标优化(EMO)算法来处理多目标(具有四个或更多目标)优化问题。作者提出基于参考点的多目标NSGA-II,称之为NSGA-III,强调非主导但接近一组提供的参考点的总体成员。提出的NSGA-III适用于许多具有2到15个目标的多目标测试问题,并与最近提出的一些EMO算法(MOEA / D)的两个版本进行了比较。虽然两种MOEA / D方法在不同类别的问题上均能很好地发挥作用,但发现我们提出的的NSGA-III在本研究中考虑的所有问题上都能产生令人满意的结果。
核心
基于多目标算法NSGA-II的基础上,提出了中参考点的方法,强调种群成员是非支配的并且与所提供的参考点距离很近。主要用于在处理超目标优化问题中解决非约束条件和约束条件下。
动机
首先,非支配解的比例在随机选择目标向量集中与目标的数量呈指数相关(非支配解的比例随目标数量的增加而成指数增长),因为非支配解占据了种群中大部分位置,任何精英保护的EMO都很难容纳下足够数量的种群中的新解,这大大减慢了搜索过程。其次,实现多样性保存(类似于拥挤度距离和聚类)将是一项计算耗时非常大的操作。最后,超维前沿可视化是一个很困难的任务,因此导致了后续决策任务和算法性能评估的困难。总结来说,性能指标(如超维度度量或其他度量)要么在计算上太昂贵,要么没有意义。
大多数多目标进化算法在求解目标维数较低的问题时较为有效,当目标数目大于等于3的时候,也就是面对高维目标优化问题,很多方法由于维数增多选择压力下降,效果变得不理想。NSGA-III的框架基本和NSGA-II相同,同样利用快速非支配排序将种群个体分类进入不同的非支配前沿,不同的是:对于在临界层中的环境选择,NSGA-II的方法是利用拥挤比较操作来选择从而保持多样性,NSGA-III最大的变化就是利用良好分布的参考点来保持种群的多样性。在选择过程中,将拥挤度距离改为参考点法(因为我们要解决的是超目标优化问题,NSGA-II中的拥挤度距离法在平衡算法的多样性和收敛性表现得并不好),限制于解决各种无约束问题,如归一化、缩放、凸、凹、收敛于PF面的一段。
1.参考点的产生
参考点既可以以结构化的方法预定义也可以由使用者提前提供。论文中使用的是Das and Dennis提出的边界交叉构造权重的方法,将参考点放在一个标准化的超平面上。
在目标空间中,一个维度为(M-1)标准单纯形(如3目标的话,那么该单纯形就是个平面),它对所有的目标轴都有相同的倾斜度。如果考虑沿着每个目标方向分为p份,参考点H的总数就可以计算出来。比如在一个三目标(M=3)的问题中,参考点在一个顶点为(1,0,0),(0,1,0)和(0,0,1)的三角形上产生。如果每个目标轴分为4部分(p=4),那么参考点的个数H=15。
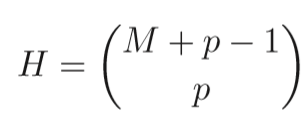
计算公式如下:
其中M为目标数目,p为每个方向上分割的份数。

但是,该方法有一个严重的缺点,就是分割份数p的大小的会影响中间点产生的情况,而如果想产生中间点,在目标维度较大的情况下,参考点数量则会急剧增加,因此为了避免这种情况,论文提出采用两层参考点产生方法,增加了内层,这样既能保证中间点的产生也不会使得参考点数目过多。
解释NSGA-III中定义参考点和NSGA-II中使用拥挤距离的区别,随机生成N个个体的初始种群,N为种群大小。P{t}为第t代时的种群,Q{t}为P{t}经过交叉、变异(参考遗传算法)后生成的种群,R{t}为两种群之和。显然,R{t}和Q{t}的大小都为N,R{t}的大小为2N,此时将R{t}中非支配排序的解放入S{t}中,若S_{t}的大小刚好为N,则相安无事。若小于N,那么继续寻找下一个非支配层,直到首次大于N。
参考点法:假设F{l}为S{t}中首次大于N层的最后一个非支配层,其中{F{1},F{2},…,F{n-1}}为前面的非支配层,参考点法的目的就是为了找出F{l}中的N-S{t}个最优个体,并入到S{t+1}中。

2. 标准化目标空间
也就是种群成员的自适应标准化,在这个过程中较难理解的是极值点是如何得到的,下面简述大体步骤,重点分析极值点的产生。
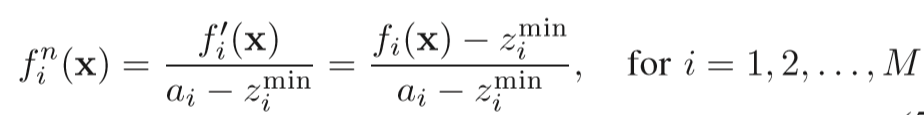
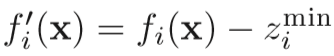

以最小化为例,首先得到种群St中的所有个体在每一维目标上的最小值,构成当前种群的理想点,然后将所有个体的目标值,以及理想点以此理想点为参考作转换操作,这时理想点变为原点,个体的目标值为转换后的临时标准化目标值。然后计算每一维目标轴上的极值点,这M个极值点组成了M-1维的线性超平面,这时可以计算出各个目标方向上的截距。然后利用截距和临时的标准化目标值计算真正的标准化目标值:
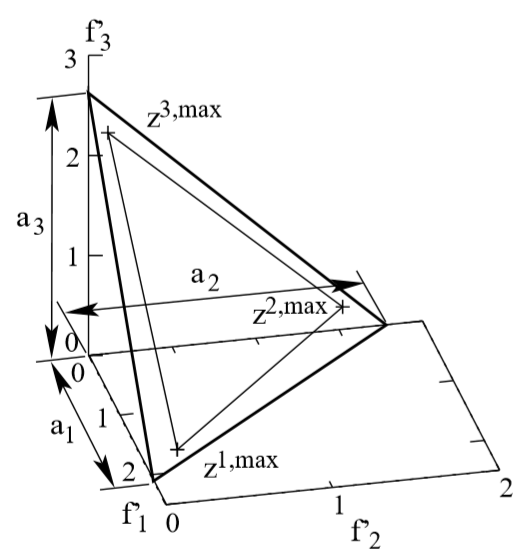
其中ai为各维目标方向上的截距。针对三个目标问题,显示了计算截距然后从极点形成超平面的过程。
下面详叙极值点的产生方法:
计算每维目标方向(目标函数)上的极值点,就是在该维上目标值很大,在其他维度上很小的点所对应的个体所对应的目标值。
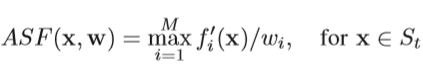
论文中利用将权重向量w作为坐标轴方向的achievement scalarizing function得到极值点:为了计算第i维目标轴上的极值点,需要固定一个目标方向,则该方向向量wi=1,其他方向的权重设为10e-6无限接近0,则权重向量w=(1,10e-6,…)固定了,然后将下面的ASF函数作为目标函数进行最小化求解,得到的就是该目标方向上的极值点,ASF函数:
举个3目标的例子,解释该过程:我们初始化种群后,会得到很多个体,他们的目标值可能是(1,0.4,0.5),(2,4,0.8),(0.3,0.6,5)等等,如果有一些点如果在某个目标上的值很大,在另外两个目标上的值很小,则这类点更靠近该目标轴,它们就是所谓的极值点,目标就是找到在一个方向上值很大,另外两个目标值很小的点,但是我们可能得到很多这样的点,这样就需要选择其中最小的作为极值点,所以是一个最小化问题。三个目标的问题话可以找到三个这样的极值点。在ASF方程中,固定第一个坐标轴,权重向量w=(1,10e-6, 10e-6),那么(1,0.4,0.5)/w,这个时候最大的肯定是0.5这个方向,得到值0.5 x 10e-6。另外两个点同样计算得到:(2,4,0.8)在ASF后变为0.8 x 10e-6,(0.3,0.6,5)在ASF后变为0.6 x 10e-6,然后选取这三个值中最小的对应的点作为极值点,可知:0.5 x 10e-6是最小的,对应(1,0.4,0.5)是最合适的极值点。我理解的是:因为我们得到的极值点是想更靠近该目标方向的坐标轴。
3、关联操作
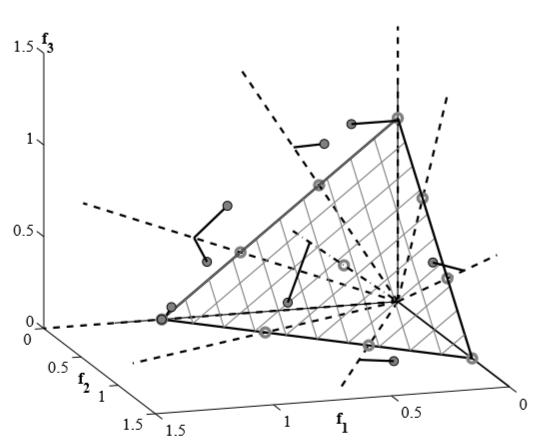
参考点设置完成后,要进行关联操作,我们要让种群中的个体分别关联到相应的参考点。为了这个目的,我们定义一个参考线,它是原点与参考点在目标空间的连线。有了参考线后,我们计算种群St的每个个体到参考线的垂直距离。然后个体与和它最近的参考线关联起来。
4.环境选择操作
这是从临界层FL中选择k个个体加入到下一父代Pt+1的操作。在上面的关联操作后,可能会出现以下情况:
1.参考点关联一个或多个个体;
2.没有一个个体与之关联。
NSGA-III记录了参考点在集合Pt+1=St/FL中所关联的个体数目,将这个小生境计数记为ρj,它是第j个参考点关联的个体数目。个体保留操作:首先我们选择ρj最小的参考点,如果有多个这样的点,那么随机选择一个即可。如果ρj=0,就表示集合Pt+1=St/FL中没有与之关联的点。
那么在FL中会出现以下两种情况:
(1)在FL中存在一个或多个个体与之关联,则将离它最近的个体与之关联,并将该个体加入到Pt+1中;
(2)在FL中不存在个体与他关联,那么在余下的操作中就不考虑该参考点。如果ρj≥1,表示Pt+1=St/FL中已经有一个个体与该参考点关联,如果FL中有个体与之关联,随机选择一个,将该个体加入到Pt+1中。重复以上操作指导Pt+1的大小等于N。
总结
在看NSGA-III的论文时,感觉归一化(Adaptive Normalization of Population Members)这一部分比较难理解,特别是里面提到的ASF函数。我觉得可以一边看论文,一边看NSGA-III的代码实现,加深理解。
大多数多目标进化算法在求解目标维数较低的问题时较为有效,当目标数目大于等于3的时候,也就是面对高维目标优化问题,很多方法由于维数增多选择压力下降,效果变得不理想。NSGA-III的框架基本和NSGA-II相同,同样利用快速非支配排序将种群个体分类进入不同的非支配前沿,不同的是:对于在临界层中的环境选择,NSGA-II的方法是利用拥挤比较操作来选择从而保持多样性,NSGA-III最大的变化就是利用良好分布的参考点来保持种群的多样性。

