
SQL 是一个描述性语言,用户描述需要的数据是什么样的逻辑,优化器决定根据什么样子的路径得到数据。
一条 SQL 首先经过语法解析(Parser),生成抽象语法树(AST),然后进行语义分析后,第一阶段对逻辑计划进行改写(Planner),改写中会引入很多规则(Rule)。改写查询计划(Plan)后,会生成多个候选的 plan,通过代价模型(Cost)估计进行优化查询计划,从中挑出一个最优的执行计划,交给查询引擎执行。
概括性的来说就是,改写查询计划过程称之为 RBO优化,优化查询计划和代价估算称之为 CBO优化。
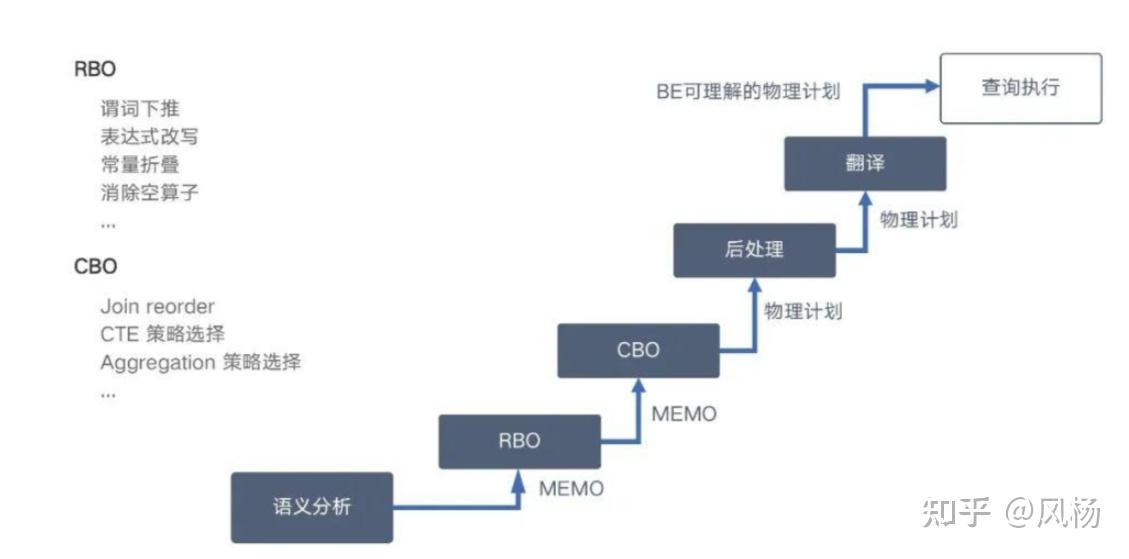
在 RBO优化规则中,包括了:谓词下推、表达式改写、常量折叠、消除空算子、函数下推、子查询去关联化、列裁剪、短路径优化查询、启发式Join Reorder(超多张表)、优化中断(在优化阶段就可以感知查询结果一定不存在,如谓词条件主键id=1 and id=2)等等。
这些Rule通常会降低查询数据的总量,因此带来了查询的效率的提升。
在优化器的实现中,一组规则Rule被反复使用也是很常见的情况。
当 RBO 改写完成后,生成的 plan 作为 CBO 阶段的输入。
CBO 阶段最主要的任务是决定 join 的顺序。因为 join 的顺序对 plan 的影响是非常大的。除了 join 顺序的选择,还有许多需要代价估算的点,包括不限于:
- CTE,即一些 with 语句生成的 view,是进行单独计算还是通过join的方式加入到查询中
- 聚合选择策略,是一阶段、两阶段、三阶段或者四阶段
以 TPC-H Q7 举例:
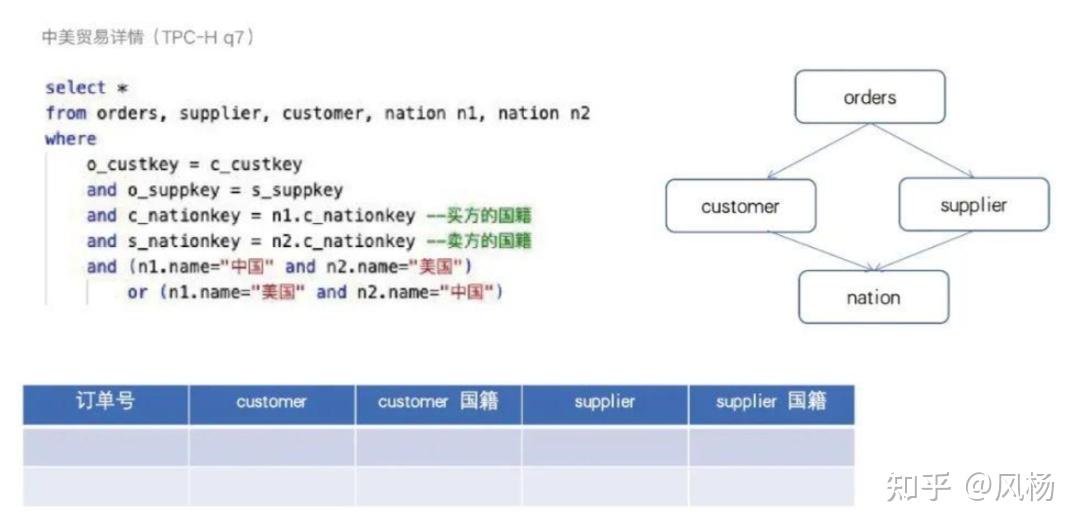
上面的SQL中,描述的是有很多订单,订单的买方和卖方都有国籍,需要选出中国和美国之间贸易往来的订单,生成一个输出结果供业务方使用。
根据条件:
(卖方的国籍=中国,并且买方的国籍=美国)或者(卖方的国籍=美国,并且买方的国籍=中国),表示中美之间往来的订单,这个条件是一体的,分开之后就会导致错误的业务结果。
查询检索的方式包括如下几种。
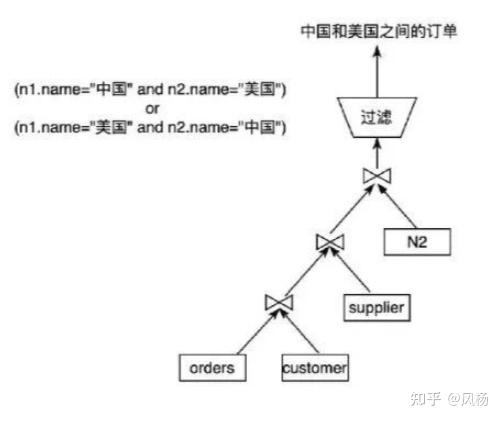
把 orders 表和 customer表先 join形成临时结果T1,然后T1和 supplier 表 join形成临时结果T2,T2再和 nation join形成临时结果T3,最后T3根据上述条件做过滤。这种方式最终处理的数据量为 `count(orders) * count(customer) * count(supplier) * count(nation)`, 当然了,最终这个庞大的笛卡尔积不用算了,铁定效率很低。
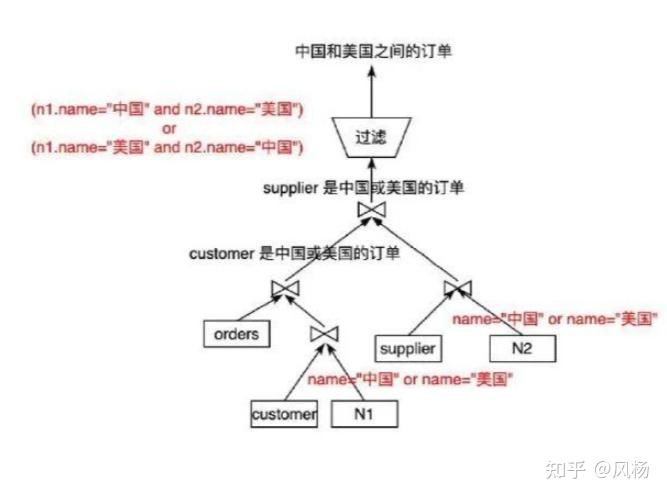
另外一个思路是,根据查询约束(中美之间的贸易)可以推导出一个条件:`customer 只选出中国或美国的 customer,supplier 只选出中国或美国的supplier`。
这里就可以有优化器的优化作为了。虽然这些额外的谓词会看似冗余件,但通过这些条件无疑可以极大地减少第一种方式中每个表的count数量,因为可以帮助我们尽早将 customer 和 supplier 的关联数据总量极大地降低。更少的数据量再与 orders 表做 join 时,右表的数量就不再是全体 customer,而只是 customer 的一部分。再和 supplier 做 join 时,右表的数量也只是一部分的 supplier,左表的数量也不是全体的 order,而只是 customer 是中国或美国的 order,所以对这个 join 来说,也极大的降低了数据量的读取和过滤。通过上述做法, 在 TPC-H 查询中的性能提高是非常显著的。
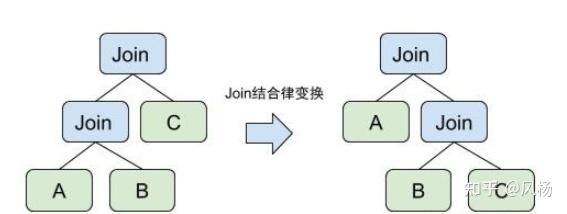
Join Reorder是通过Join的交换律、结合律等规则来实现的。
在事实表和维度表做Join的时候,往往维度表会有一些过滤条件,会对事实表有很强的过滤效果。多表在Join时的顺序不同,会带来完全不同的性能表现。因此调整 join 的顺序也是优化器的一个重要只能。
下面是一条Join结合律转换规则的示意图,规则匹配了两个特定顺序的Join,并将它转换成了另外一种Join顺序,这样我们就从原有的执行计划得到了一个等价的执行计划!这两个这行计划在执行结果上是完全等价的,但可以各自算出自己的代价并比较大小,来抉择出一个最优解。
举个例子实际说明下。还是上面的示意图,以三张表 A join B join C 为例,各表行数和 join 结果如下图所示:
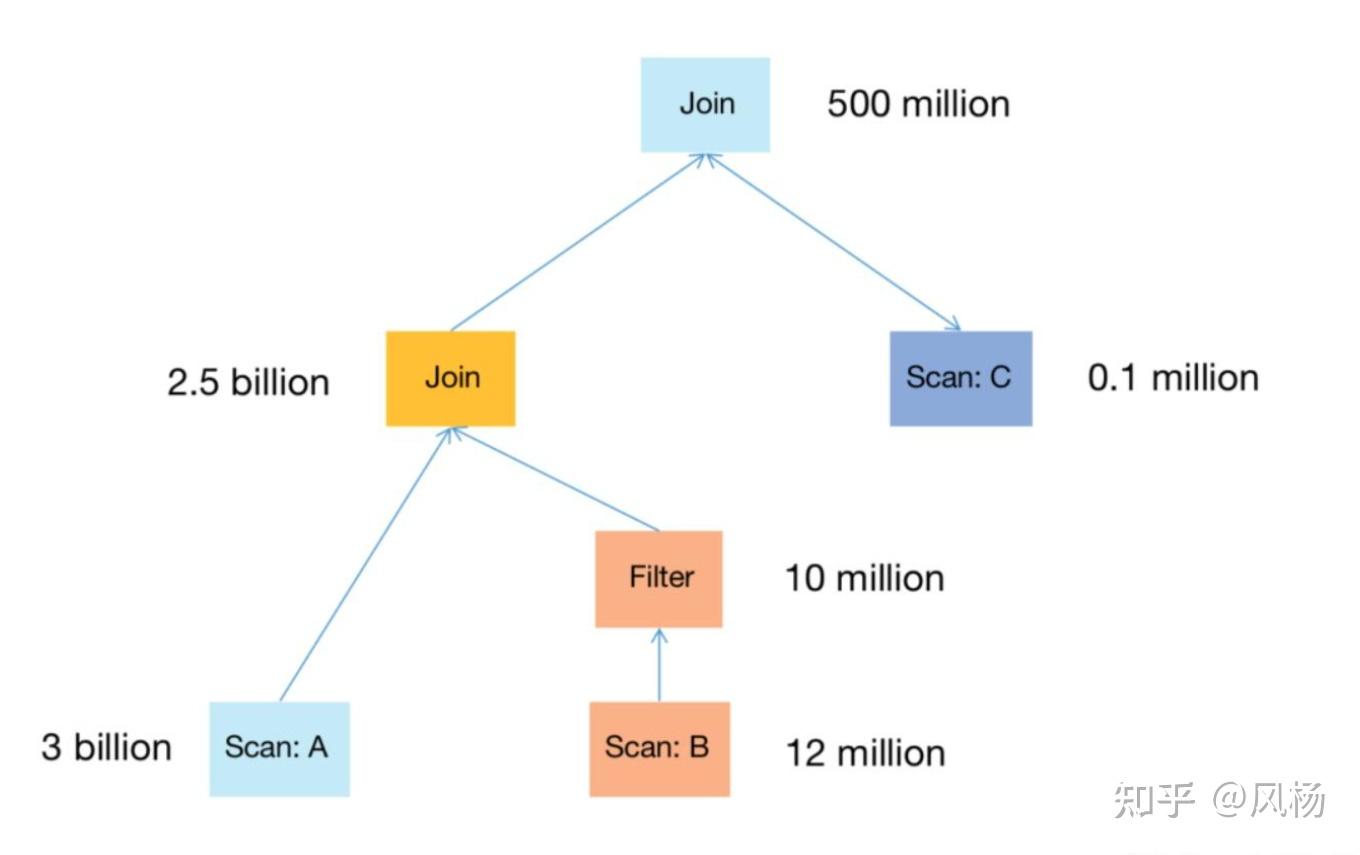
经过 CBO Join Reorder 优化后,会对 join 顺序做如下调整:
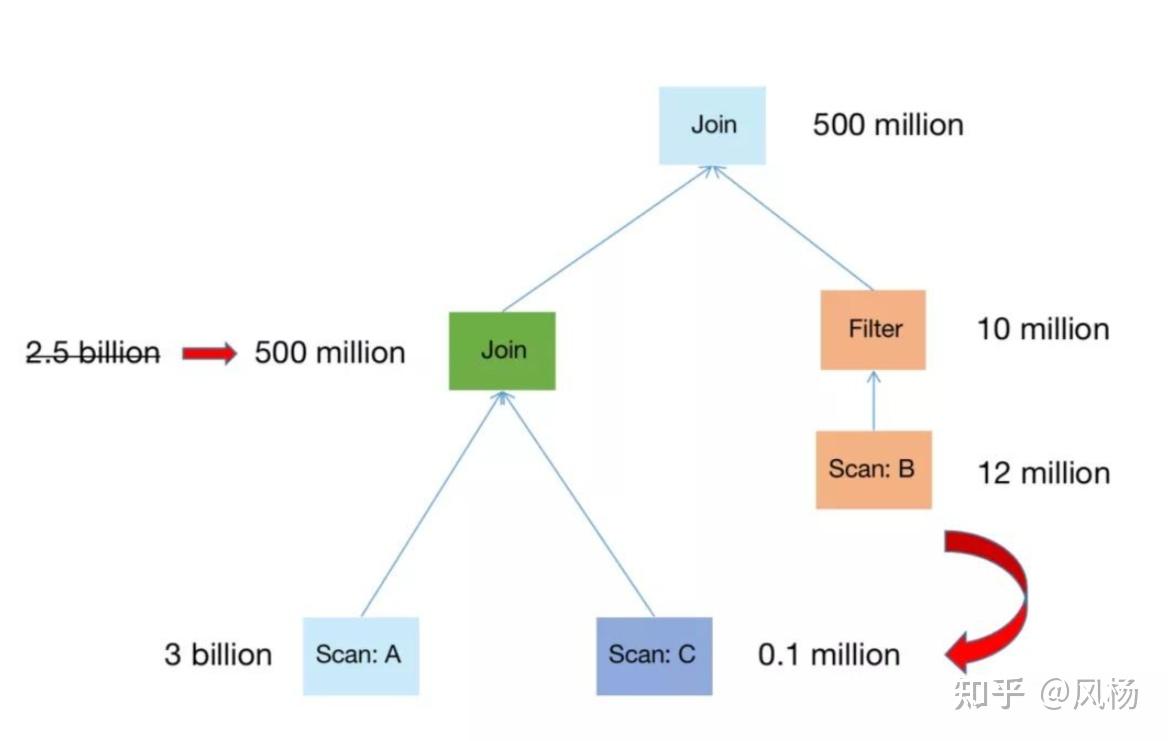
调整顺序后,先 A join C,使得中间结果相比默认 A join B 的方式,从 2.5 billion 行下降到 500 million 行。这样,和第三张表的 join 数据量就减少了 80%,整个查询的性能也就大幅提升了。
这个优化,是 RBO 无能为力的,你无法总结出一条规则,来决定哪个表应该放在前面。
当我们加入更多的规则去枚举遍历的话,我们就可以搜索更大的搜索空间。搜索空间的控制大小在优化器中有着非常多的考量,特别是Join Reorder会产生大量等价的执行计划。
另外,Join Reorder是作用于逻辑算子树且生成逻辑算子树的,执行计划的逻辑转换就是通过一系列的逻辑转换规则来完成的。
但是这时候又面临一个问题:我们知道 Join Reorder是一个 NP的问题,当表的数量增加时,候选 Plan 会呈几何级数增长。通常NP 问题一般只能通过动态规划的方法,找一些次优的解。现在出现的所有解法,都是动态规划不同的应用方式,比如有:DPSize、DPSub、DPhyper、Cascading。当然这些不同的方式可以同时实现,相互补充。
Join Reorder 部分,后续写hypergraph算法部分的时候在一起探讨。
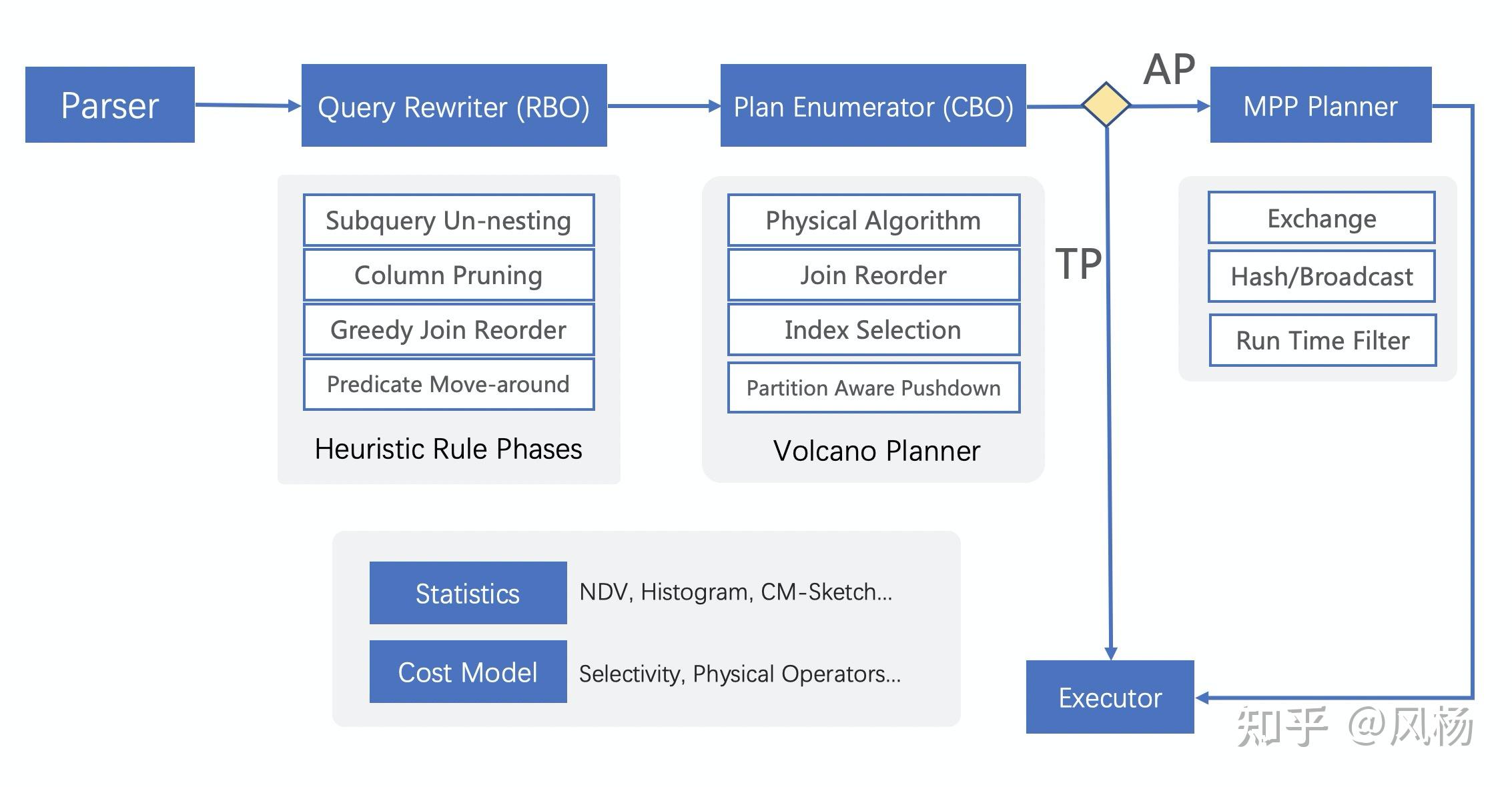
优化器接受到SQL后会将它解析、转换成由关系代数算子组成的逻辑执行计划。基本上优化器中优化实现过程手段都会通过转换规则(Transformation Rule)来表达,转换规则会匹配特定结构的关系代数算子并将其转成等价的算子。
优化器的优化阶段主要分为三步:
- Query Rewriter,基于RBO的启发式优化阶段,逻辑优化规则在优化的本质中已经讲过,不再陈述。这个优化阶段的特性是不断启发式地对同一个执行计划做逻辑优化,优化通常很快,且只做收益非常明确的优化器。
- Plan Enumerator,基于CBO的Volcano/Cascades模型,是最为核心优化阶段,它会应用转换规则为计划生成搜索空间,既包含了逻辑优化如:Join Reorder(Bushy、Zig-Zag、Left Deep空间动态选择)、算子交换、计算下推等,也包含物理优化如:全局二级索引选择、物理算法选择等。搜索空间被完全展开并搜索过后,每个物理执行计划都会根据具体的物理算子估算出执行所需要的代价(通过CPU/MEM/IO/NET表示)。最后代价最低的物理执行计划将会被选择出来。在整个优化过程中,这一步耗时占比最高,因为它需要考虑整个搜索空间。
- MPP Planner,多机并行计算优化阶段,处理并行算子生成,算子间Shuffle的选择与消除,RunTimeFilter的生成及下推等。这一优化阶段专门用于优化OLAP的查询,保证可以充分利用多个节点的计算资源。
此外还有统计信息(行数,直方图,列长度,NDV值等)、代价模型、基数估计(Cardinality Estimation)等其他的基础组件/模块,好的优化效果依赖于准确的数据统计信息。
以 PolarDB-X 举例,分析 TPC-H Q3 的优化执行。
此处需要说明的是,每种数据库对于优化器的执行大同小异,对于每个阶段或者阶段算子的命名存在些许差异。如 PolarDB 中的最底层算子为LogicalVIew,而 Trino/Presto 最底层算子命名为 TableScan。(在优化器层面可以类似的去类比,但不是相同哦)
这个SQL完成的业务是:运送优先级查询。
select
l_orderkey,
sum(l_extendedprice*(1-l_discount)) as revenue, //潜在的收入,聚集操作
o_orderdate,
o_shippriority
from
customer, orders, lineitem //三表连接
where
c_mktsegment='BUILDING' //在TPC-H标准指定的范围内随机选择
and c_custkey=o_custkey
and l_orderkey=o_orderkey
and o_orderdate < '1995-03-15' //指定日期段,在在[1995-03-01, 1995-03-31]中随机选择
and l_shipdate > '1995-03-15'
group by //分组操作
l_orderkey, //订单标识
o_orderdate, //订单日期
o_shippriority //运输优先级
order by //排序操作
revenue desc, //降序排序,把潜在最大收入列在前面
o_orderdate;查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前10行(通常依赖于应用程序实现)。
Q3语句查询得到收入在前10位的尚未运送的订单。在指定的日期之前还没有运送的订单中具有最大收入的订单的运送优先级(订单按照收入的降序排序)和潜在的收入(潜在的收入为l_extendedprice * (1-l_discount)的和)。
Q3语句的特点是:带有分组、排序、聚集操作并存的三表查询操作。
我们把排序去掉,该语句在被优化器处理后,被被转变为逻辑执行计划(LogicalPlan),如下图呈现的结构:
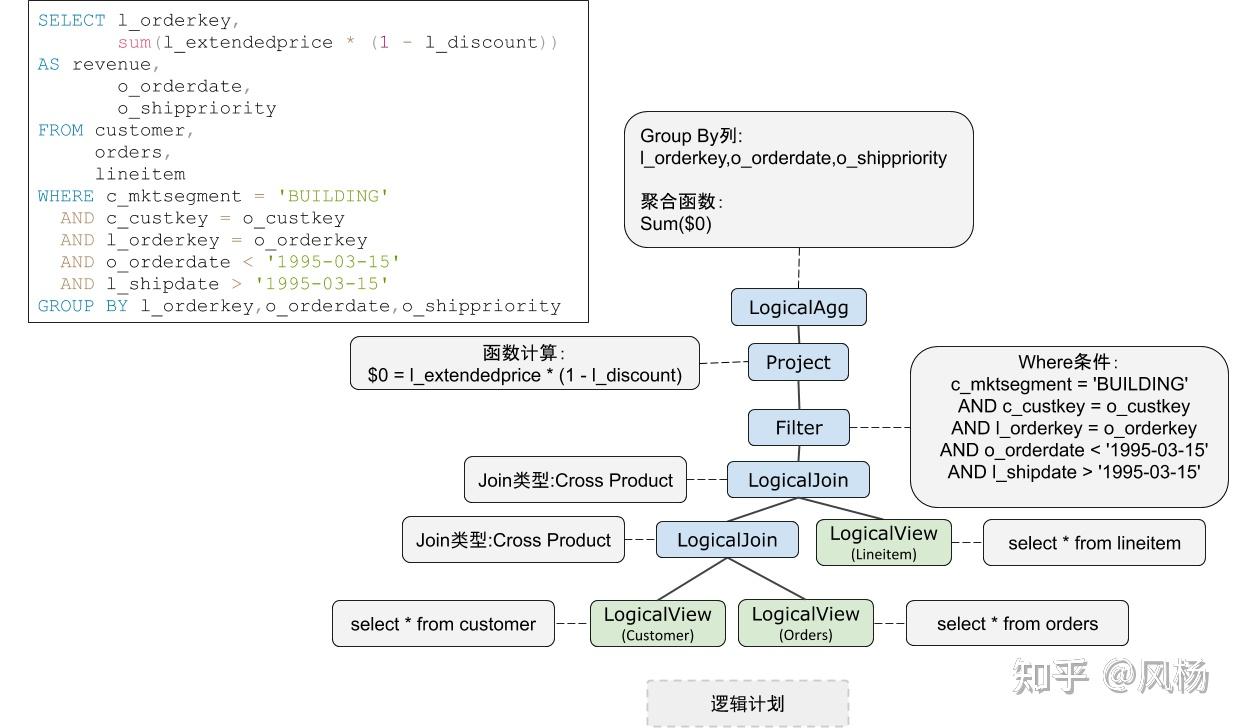
上图,这个逻辑执行计划包含Agg、Join、Filter、Project、LogicalView等关系代数算子,PolarDB-X通过LogicalView算子来抽象下发至存储执行的Plan(所以下推算子在优化中就是将算子下推进LogicalVIew算子)。
接下来继续看每一种优化的RBO,CBO,MPP优化特色。
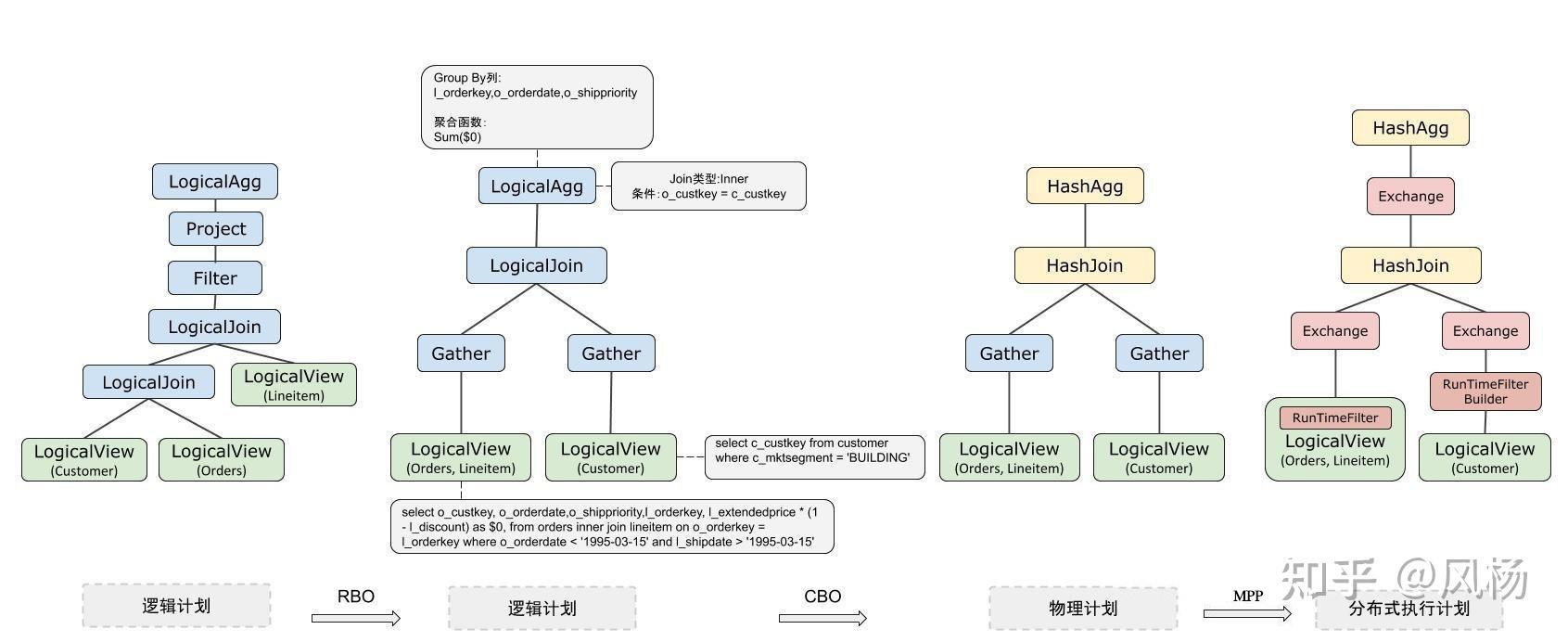
- RBO阶段,一般为启发式RBO。可以看到经过RBO优化之后,逻辑执行计划已经将Filter、Project等算子下推到了LogicalVIew,也就是列裁剪、谓词下推等优化处理。同时也可以看到原来Orders、Lineitem表也因为拥有相同拆分规则被下推到了同一个LogicalVIew,完成了计算的下推优化。
- CBO阶段,是基于代价的优化。可以看到逻辑执行计划变成了物理执行计划,其中Join和Agg分表选择使用HashJoin和HashAgg作为物理算子。在这背后,优化器实际上已经考虑了不同的Join顺序,不同的Join与Agg算法,被选择出来的就是具有最低代价的物理执行计划。
- MPP分布式优化阶段,在算子间多了Exchange算子,用于描述数据如何在多个计算节点间进行Shuffle。这使得执行器可以知道如何在多个计算节点中传输数据,并行计算。此外,这个阶段还会可能生成RunTimeFilter计划,并下推到存储节点执行提前过滤数据,减少网络传输开销,进一步提高性能。
需要注意的是,动态过滤(RunTimeFilter)是在执行器阶段才运行的,但这不代表在优化器阶段与RunTimeFilter无关,因为在优化器阶段可能会生成、组织RunTimeFilter的运行前置条件和要素。

